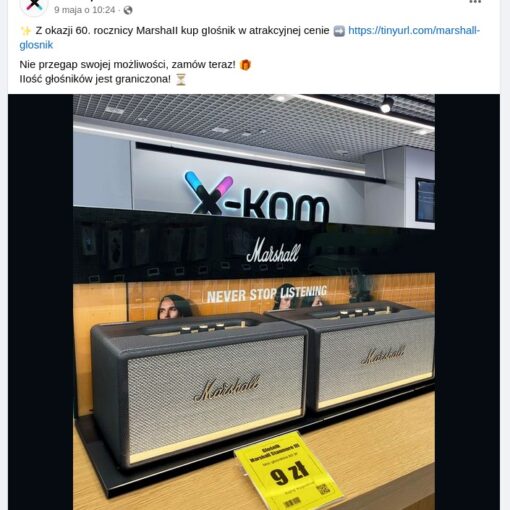
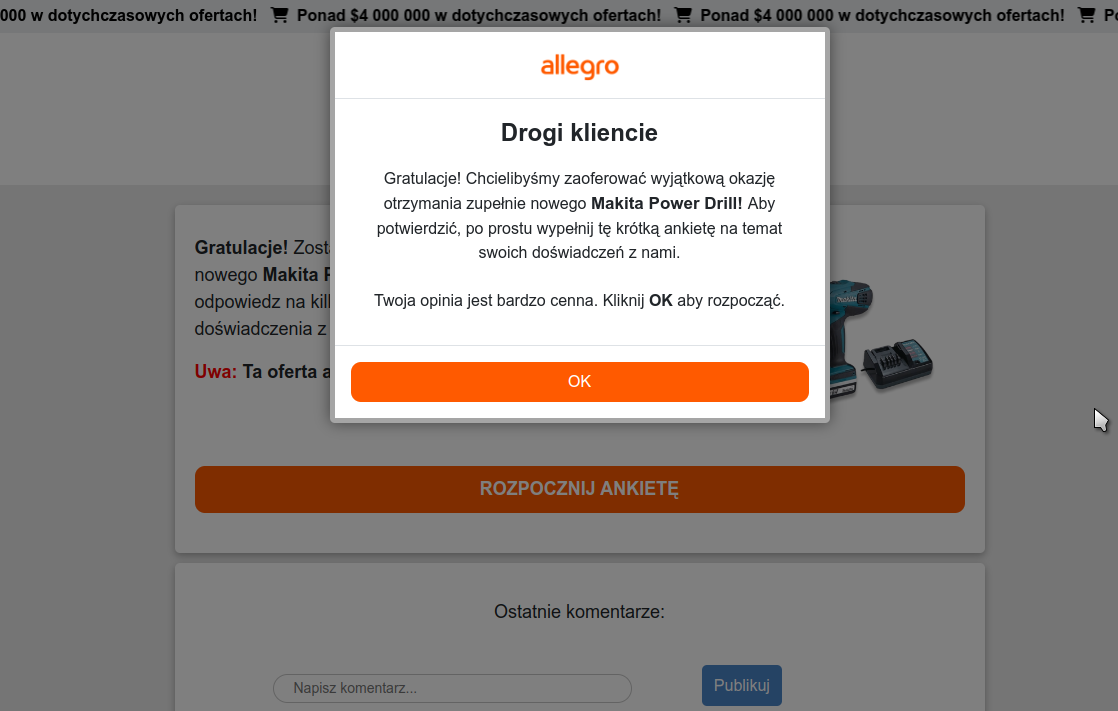
Następnie trzeba podać swój adres do przesyłki, mail i telefon (to też są dane, które przestępcy zapewne sprzedadzą do jakiejś bazy danych) i użytkownik zostanie skierowany do płatności. Jedyną możliwą jest karta płatnicza. A gdy już naiwny amator okazji wpisze dane karty, w tym kod CVV, jest na prostej drodze do utraty znacznie większych pieniędzy niż myśli.
w.trampczynski
115 wpisów
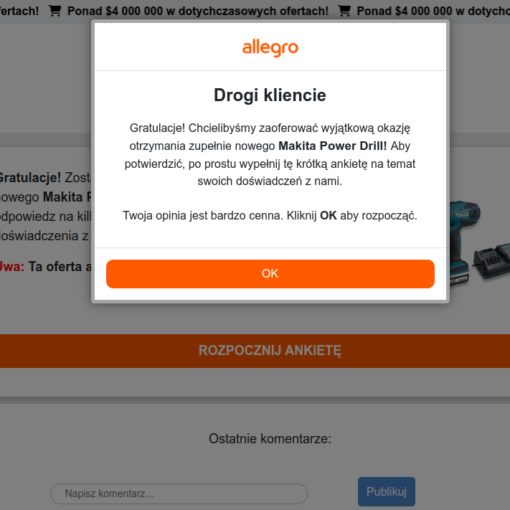
Skoro Allegro – najpopularniejszy wciąż – serwis aukcyjny wprowadza loterię powiązaną z dokonywanymi zakupami, to czego należy się spodziewać? Jeśli ktoś korzysta od lat z internetu, to nie ma wątpliwości. Na pewno pojawią się oszustwa.
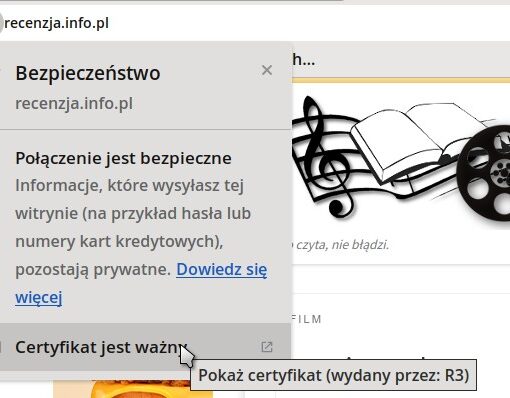
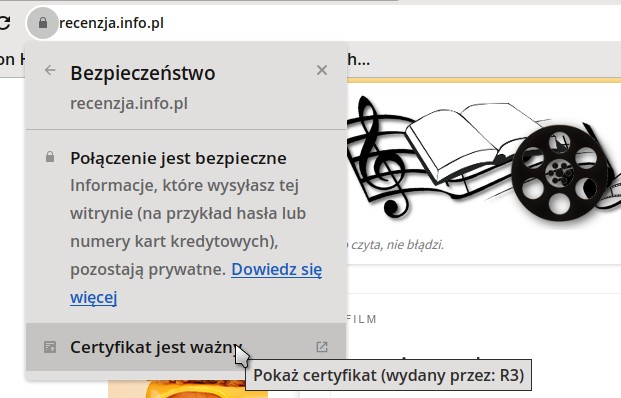
Dziś już strony www, które nie używają szyfrowanego połączenia HTTPS, są uznawane przez prawie wszystkie przeglądarki za niebezpieczne. Zwykle na samym początku już wyświetli się nam ostrzeżenie, że ta strona nie jest przesyłana i wyświetlana w bezpiecznym połączeniu i postronne osoby mogą podejrzeć np. nasze hasła, jeśli tą drogą będziemy je przesyłać.
Aplikacja „Cockpit” jest dostępna w wielu dystrybucjach Linuksa od Red Hata, Fedory i CentOS, po Debiana i Ubuntu. Zatem z reguły wystarczy użyć managera pakietów (apt-get, yum…), aby zainstalować ten całkiem przydatny panel w swojej dystrybucji.

Serwisy udostępniające pocztę elektroniczną powinny zbierać informacje dotyczące logowania do obsługiwanych przez siebie skrzynek poczty elektronicznej. Dziennik ma składać się z daty, godziny (co do jednej sekundy), adresu IP oraz portu przypisanego użytkownikowi w trakcie połączenia.

Blik staje się coraz częściej używaną formą przekazywania pieniędzy, a to znaczy, że prędzej czy później staniecie się celem ataku, mającego na celu pozbawienie was pieniędzy z konta. Zaczyna się zwykle od SMSa, który przeczytacie na swoim telefonie.
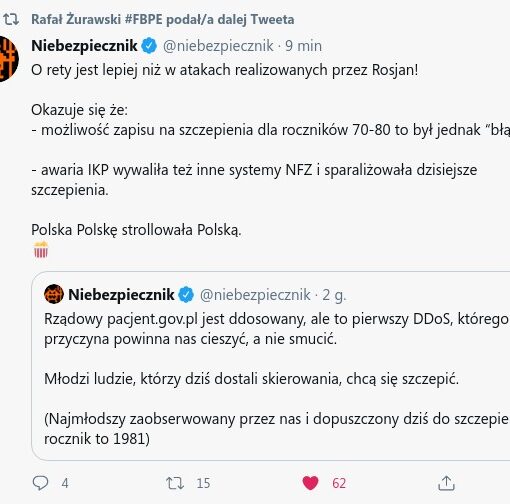
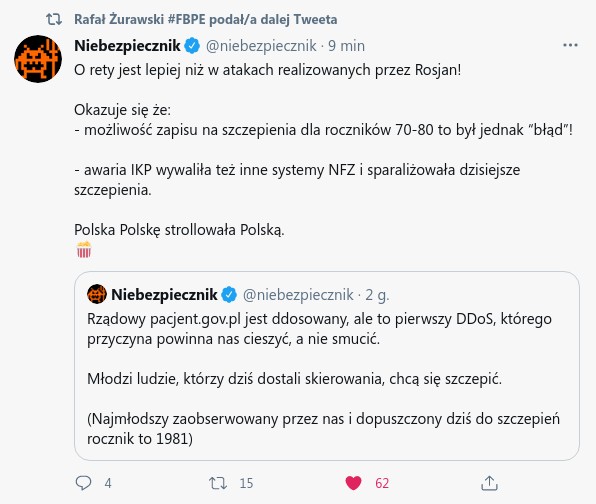
Polska Polskę strollowała Polską – taka konkluzja wyłania się z obserwacji dokonanych przez portal Niebezpiecznik. I chyba mają rację.

Od wczoraj nie działają praktycznie żadne dodatki, ani rozszerzenia w Firefoxie. Nie jest to zależne od wersji, ani od systemu operacyjnego, tylko od przeglądarki. To chyba największa wpadka programistów Mozilli od lat. Najbardziej wściekli są użytkownicy wszelkich wtyczek blokujących reklamy. Nagle zostali pozbawieni swojej strefy komfortu, a reklamy zalewają ich […]

Taki tam żart informatyków.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Już pod koniec grudnia ubiegłego roku Facebook, a dokładniej jego część zwana Messengerem, zapełnił się takimi oto wiadomościami, które przesyłali sobie użytkownicy. Bardzo często wysyłając to masowo do bliższych i dalszych znajomych.